Zizi.ai Model Training Dev Log
Working with Jake Elwes on The Zizi Project, we’re trying to build a realtime performance of zizi.
Links & Resources
- OpenPose GitHub page on inference speed
- 2018 U-Net Paper for Pose to Image generation
- Weights & Biases Article on conditional diffusion training
- MosaicML Composer list of speedup techniques
- Impersonator++ - Motion Imitation Library using GANs
- GitHub of some papers for realtime pose estimation
- YouTube tutorial making a diffusion model from scratch (with simple conditioning)
- Conditional MNIST from scratch
- In-depth explanation of VAE / Diffusion Model Maths
- ❗️ Annotated PyTorch Paper Explanations
- SD XL Paper - lots of readable content / links on how they improved or changed the model for better performance
- U-ViT GitHub - has training + eval scripts for pixel & latent models with a better arch
- Deeper dive into diffusers / training
- UNetCondition2D rewritten to be simpler
- Curated Transformers library - huggingface but if the code was good. LLMs only at the moment
2023-10-09
- Few weeks since I’ve written anything about the status here. Key changes:
- Jake has trained a vid2vid model that only takes in the openpose and had some good results - pretty close to the full denspose + flownet + openpose models used before. The performance is also good (~2.6fps on his 1080 Ti GPU). Will likely end up using this model over the diffusion models for realtime perf, given the challenges both training and using a diffusion model for inference.
- Getting the vid2vid code to work without resorting to the wild west of very specific versions of every dependency was…a challenge. Thankfully we got it working in the end without using the messy scripts and AWS AMIs Jake used, and I’ve added a
pyproject.tomlfile to the repo to ease reproducability (tbd on if it genuinely does, but it’s at least a better foundation). - The OpenPose codebase will be annoying to get working - it uses the CMake GUI to build and hasn’t been updated in a while. Sigh. Plus will need to be built with GPU (i.e CUDA) support, might not be possible from a macOS host.
2023-08-16
Modeling
- I think we should stick with a pixel-model for now - latents add a lot of complexity (and slower inference as we have to decode after denoising).
- The model I’ve been using has only had self attention blocks in the down/up-scale parts of the UNet. Switching to cross attention blocks (which is what SD uses) has not been successful. Either it OOMs trying to allocate memory for the blocks, or the loss stays fixed at 1 (and output images are 100% noise) when training. Wondering if the fact that the pose values are entirely unscaled has any big impact? The model is otherwise very similar to the non-cross attention one.
- It also seems weird that the Stable Diffusion UNet doesn’t declare the encoder dimensions or anything…not clear to me how the values align there. UPDATE: The text encoder produces vectors of 768 elements, and the cross attention dim of the model is also 768.
- Wondering if building up a UNet from scratch (vs using diffusers) might be a useful exercise in both understanding it better and also having more control/ability to debug when things don’t work as expected. Might be painful though.
Realtime Rendering
- For the realtime rendering, assuming we have a blackbox model that generates X images per batch and runs in 1 second, we can create a simple video stream by having both the model and the output video player fetch “latest X frames” from respective buffers.
- The video stream produces frames at a constant rate (say, 16 fps). A frame-consumer fetches the last second of frames, and filters them down to the number of images a single batch can process (X frames).
- We run the X frames through the model, receiving X output frames ~one second later.
- The playback reads frames at a fixed interval from the output buffer. The output buffer. If there are no new frames in time, it uses the most recently returned value. Each time there’s a new batch of images, the buffer is replaced entirely (so we don’t fall further behind the input).
- In this model, the latency would be 3 seconds - one for the input, one for the model execution, another for the output buffer.
- If we have a timestep-based diffusion model, we can use the timestepping to decrease latency. For the method above, our output stream must be 2*batch time behind the model (buffer + model runtime - basically we need to be playing a full second of video while the next second is processed). Instead of reading X frames in one go, after the initial batch we add one new frame and remove one completed frame at each timestep. This means both the input and output buffer need only a single frame (+ whatever padding improves stability) to be able to generate the video. This requires the total model runtime being relatively fast, but instead of 3*model_latency we get model_latency + timestep_latency as our performance bound.
- If a non-diffusion model is either substantially faster or not improved by batching, then there’s a big advantage to doing the naive “process the most recent ready frame and push them out” kind of approach.
2023-07-30
- After like 45 epochs, the VAE models looked dramatically worse than the pixel models. While it did keep improving, the amount of time it took - and the very blurry nature of that model - is concerning. Wondering if a. the UNet can’t handle this data format as effectively / needs a lot more training to get something or b. the latents aren’t high enough resolution or are all so close to each other in that latent space that we’re massively harming the model by using it.
- Two avenues to explore - does training our own VAE get anything decent in a reasonable amount of time? If so, are the latents good? Also, what do we get if we play with UNet architectures / maybe add some kind of upsampling directly into the UNet (e.g inputs are 256, train the UNet to produce 512 images & use loss on the original image size).
2023-07-26
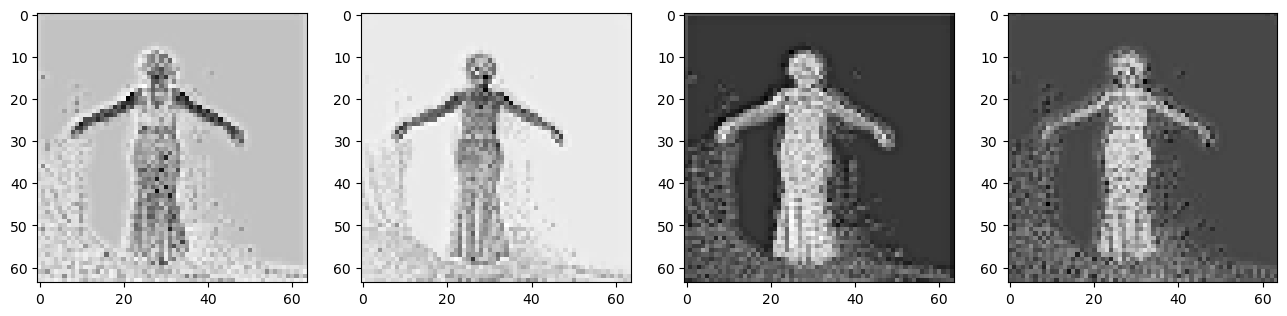
- Lets try with a VAE! First gonna train with the SD VAE and then if that gets decent results can train our own (probably smaller given very limited dataset content). One thought: VAEs encode spacially - which makes sense for detail that can be anywhere in an image. But our images don’t have detail everywhere, just where the person is. So there’ll be too much latent info in the blank bits and too little in the high-detail sections. Here’s how SD’s VAE encodes a frame of a video we’ll be encoding:
2023-07-25
- Midnight breakthrough! Trained 5 epochs with pose conditioning and it’s working surprisingly well. This would need much more training & much much higher resolution to be actually useful, but as a POC I’m pretty happy! Worth noting that this is also still all in pixel space, so we haven’t done any encoding/decoding into a lower res latent space which would make higher resolution images possible.
- Now trying out training at 512x512 resolution on an A6000 with 48GB RAM 🤑. And using better source images courtesy of Jake!
- While the training run continues, I’m playing with stable diffusion’s VAE & seeing what results we get. Pretty impressive overall - 48x fewer values and can recreate something close to the original image, although in this case the face is looking pretty poor. Presumably a well-trained VAE on exclusively zizi-like data would produce even better images (and due to the very limited content, potentially offer even better compression).
2023-07-24
- Still struggling with creating a conditional model - using diffusers consistently OOMs when I add any value for the “encoder hidden states” value & creating a VAE also oomd trying to encode a single image. I’m sure I’m doing lots wrong but so hard to know what, and none of the guides so far are at the right level (eather too basic or too complex/abstract).
- Resolved! There were a few things going wrong, as expected. First, the model was huge due to a cross_attention_dim param that defaulted to 1280. Secondly, PyTorch seems to have a weird bug that consistently OOMed on CPUs but not on CUDA (in spite of having much less CUDA memory). Finally, we figured out that the
encoder_hid_dimparam on the UNet2DConditional class allowed us to tell the model what the third param needed to be. I don’t expect this to provide particularly good results (afact theencoder_hidden_statesis for providing latents, not conditions - but this can be a fun little test right? 😇)
2023-07-23
- Did some brief inference perf testing & saw that the MPS backend can generate the meth/zizi images pretty quickly. torch.compile ran slower on my M1 mac but probably works much better on CUDA. Needed to pass in some weird
backend="aot_eager"param totorch.compileto get it to work. Link
2023-07-20
- Moving from the UNet2D class to the UNet2DConditional doesn’t seem as simple as I’d hoped. The UNet2D class basically took in raw image tensors, but for the conditional version it seems to expect an already-embedded vector to condition on. Unclear if I need to use an Autoencoder / VAE system like Stable Diffusion does, or if I can just ignore all that for now & find some simpler ways to condition the unet.
- One thought is that we don’t really have to use openpose or densepose to condition the model, we can just as well do something super cheap like an edge-finding tool or segmentation model as a way to speed up the ETE process.
2023-07-19
Going to try and find a better data source, and see how much more complex the model code is when trying to use the existing OpenPose / DensePose outputs to condition the model. In parallel, can investigate realtime OpenPose - their repo seemed to suggest that ~15fps should be achievable, which would be more than enough for our use case.
- Attempting to use run inference on the trained model seems to be very slow - looks like it’s doing 1000 steps by default. Thankfully, 50 produced reasonable results (but still didn’t run fast on the M1)
- Disappointingly but somewhat unsurprisingly, neither fp16 nor torch.compile worked nicely on the M1. Will have to switch to CUDA to see what optimal perf can be.
2023-07-18
The existing zizi models use some combination of openpose, densepose, and vid2vid. This makes them pretty unsuitable for realtime performance, and misses out on a lot of the improvements that have come from the diffusion model world (in contrast to the GANs that vid2vid uses). Instead of trying to make the existing models faster performing, I wondered if it was worth just training a new model from scratch - given that Stable Diffusion has support for OpenPose / DensePose, it seemed likely we could build a similarly controlable model ourselves.
Trained a model based on the simple “train a diffusion model” HuggingFace tutorial. As a first-attempt, I wanted to get a ballpark sense of what kind of results would be possible.
I trained this model on about 500 images of Me the Drag Queen from one of Jake’s videos, first on my M1 MBP and then on Google Colab (free) and on 2x 3090 RTX GPUs rented through vast.ai. The end result was encouraging - the generated images looked pretty close to the original after 50 epochs:
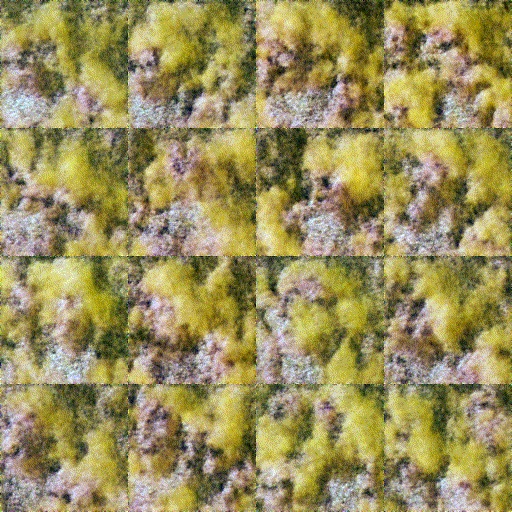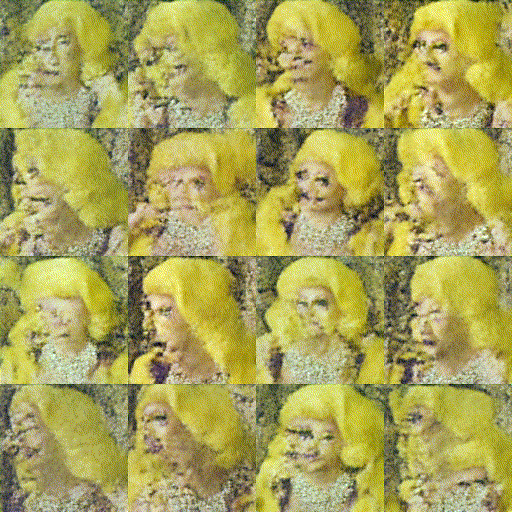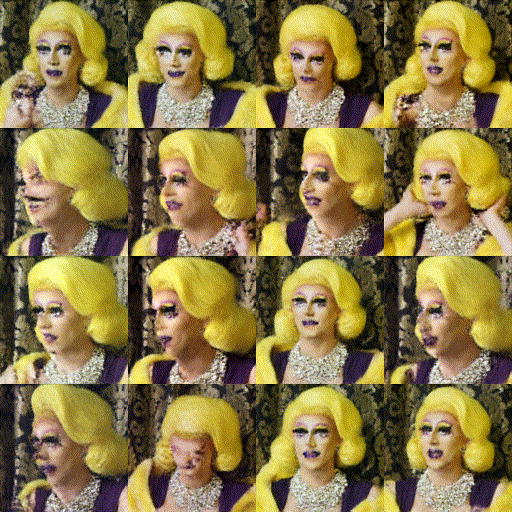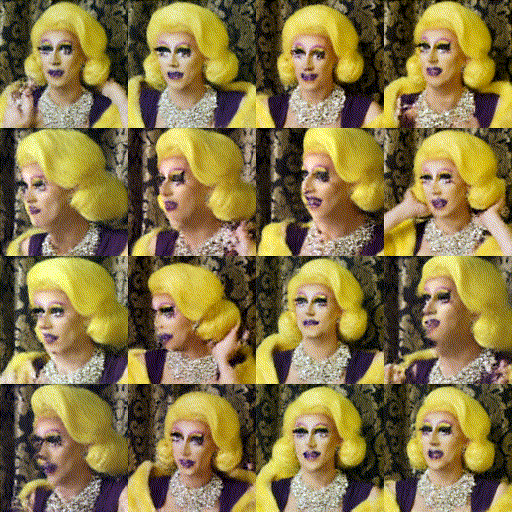
Sadly, of the three training runs the M1 MBP was by far the slowest - about 2x slower than the Google Colab T4 GPU and dramatically slower than the 2x 3090s.
The development process was pretty smooth - didn’t have to make many code changes between environments. Only wrinkle was getting multi-gpu working - ran into the CUDA shared memory issue when trying to start from a notebook (even without running code in any cells), so converted it to a script and used accelerate launch ... - much easier. Not too much work bad for that level of perf improvements at least.
Only big surprise is the size of the model binary - about 450MB. The input data is only 65MB, so not clear what’s causing that much bloat.